Chapter 7 Component architecture
7.1 Principles of modular architecture
The Enterprise Digital Twin (EDT) platform builds on the principles of modular architecture, which gives it flexibility, scalability, and the ability to roll out in stages. The modular approach lets you tailor the system to a specific enterprise by connecting only the components you need.
Key principles of modularity:
1. Module independence
Each module is a self-contained functional unit with a clearly defined interaction interface. Teams can develop, test, and update modules independently of one another, which lowers the risk when you introduce changes.
2. Loose coupling
Modules talk to each other through standardized APIs, which minimizes the dependencies between components. Changing the internal implementation of one module does not force you to modify the others, as long as the interface stays the same.
3. High cohesion
Each module concentrates logically related functionality in one place. The forecasting module, for example, contains everything you need to build and run forecast models.
4. Reusability
We design modules as general-purpose components that work across different projects and industries. The balance-calculation module, for example, serves both the chemical industry and the agro-industrial sector.
5. Scalability
Modular architecture lets you scale individual components horizontally based on load. You can deploy compute-intensive modules on dedicated, high-performance servers.
Standard platform modules:
- Data management module — collects, normalizes, stores, and serves access to data;
- modeling module — builds structural-technological schemes and balance models;
- optimization module — solves linear and nonlinear programming problems;
- forecasting module — time series, machine learning, scenario analysis;
- visualization module — dashboards, reports, interactive charts;
- integration module — REST API, ETL processes, connectors to external systems;
- administration module — manages users, access rights, and configuration.
Modular architecture supports a staged rollout: the customer can start with the basic modules (data management, visualization) and gradually connect advanced functionality (optimization, machine learning) as readiness and need grow.
7.2 Technical components of the system
The component architecture of the EDT rests on a microservice approach, where each component owns its own area of functionality. The software runs on open-source R libraries and includes high-performance computing modules written in Java and C++.
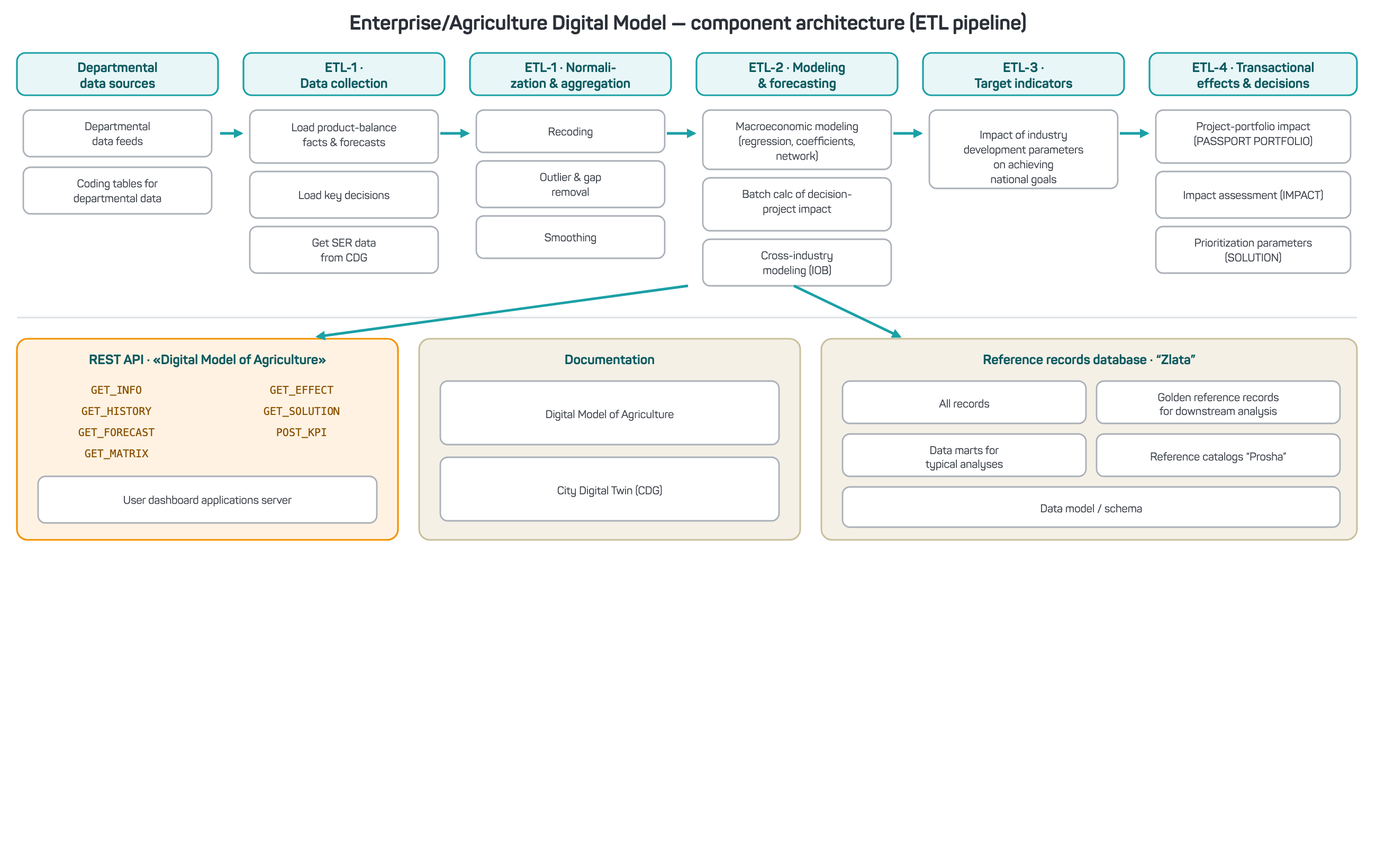
Figure 37 — Component architecture of the EDT
The microservice architecture delivers scalability and flexibility, letting you add or remove components on the fly without disrupting the other parts of the system.
7.3 Data processing stages
7.3.1 Data ingestion and processing stage
ETL (Extract, Transform, Load): ETL technology handles collecting data from various sources, transforming it, and loading it into the central repository. Data can come from the enterprise’s internal systems as well as from external sources (for example, Rosstat, the Federal Tax Service, APIs).
API integration: Lets the system pull data in real time from various sources, which keeps calculations and analysis current.
Data normalization: The system normalizes data automatically, bringing it to a single standard and removing duplicates, gaps, and format errors.
In practice, the system combines open and closed data sources: Rosstat, the Federal Tax Service, the Federal Customs Service, the FGIS “Zerno” grain system, exchange data (FOREX, CME, CBOT), the WTO, and socio-economic development data for countries worldwide. The figure below shows the data collection pipeline for a deployment in the agro-industrial sector.
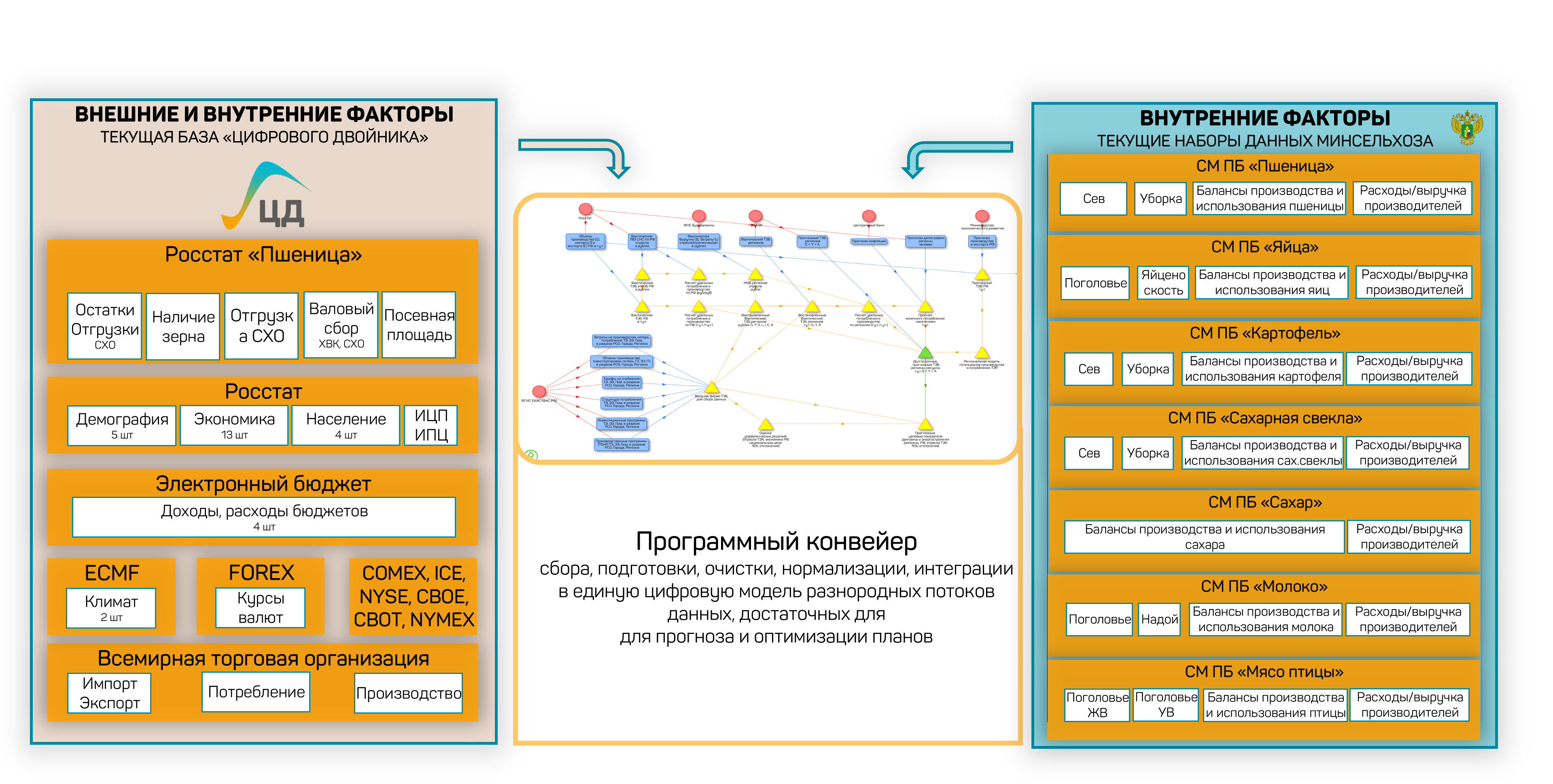
Figure 38 — Data sources and collection pipeline: open and closed sources
7.3.2 Calculation and analytics stage
Java and C++: High-performance calculations run on Java and C++ modules, which lets the system process large volumes of data with minimal latency.
R (Posit): Supports the complex statistical and mathematical models needed for scenario modeling, factor analysis, and forecasting.
Targets: Organizes calculation nodes and manages their dependencies. This technology tracks whether data and calculations are current, supports versioning of calculation models, and enables repeated parallel computations.
Balance models: The system supports intersectoral and interterritorial balance models, as well as a resource-balance model, which serve to assess the enterprise’s resource needs and allocate them optimally.
Take wheat production as an example: the technological scheme covers the full cycle — storing imported products, growing and harvesting the crop, sales, storage, livestock feeding, export, and processing. Each block ties to physical, cost, and forecast indicators.
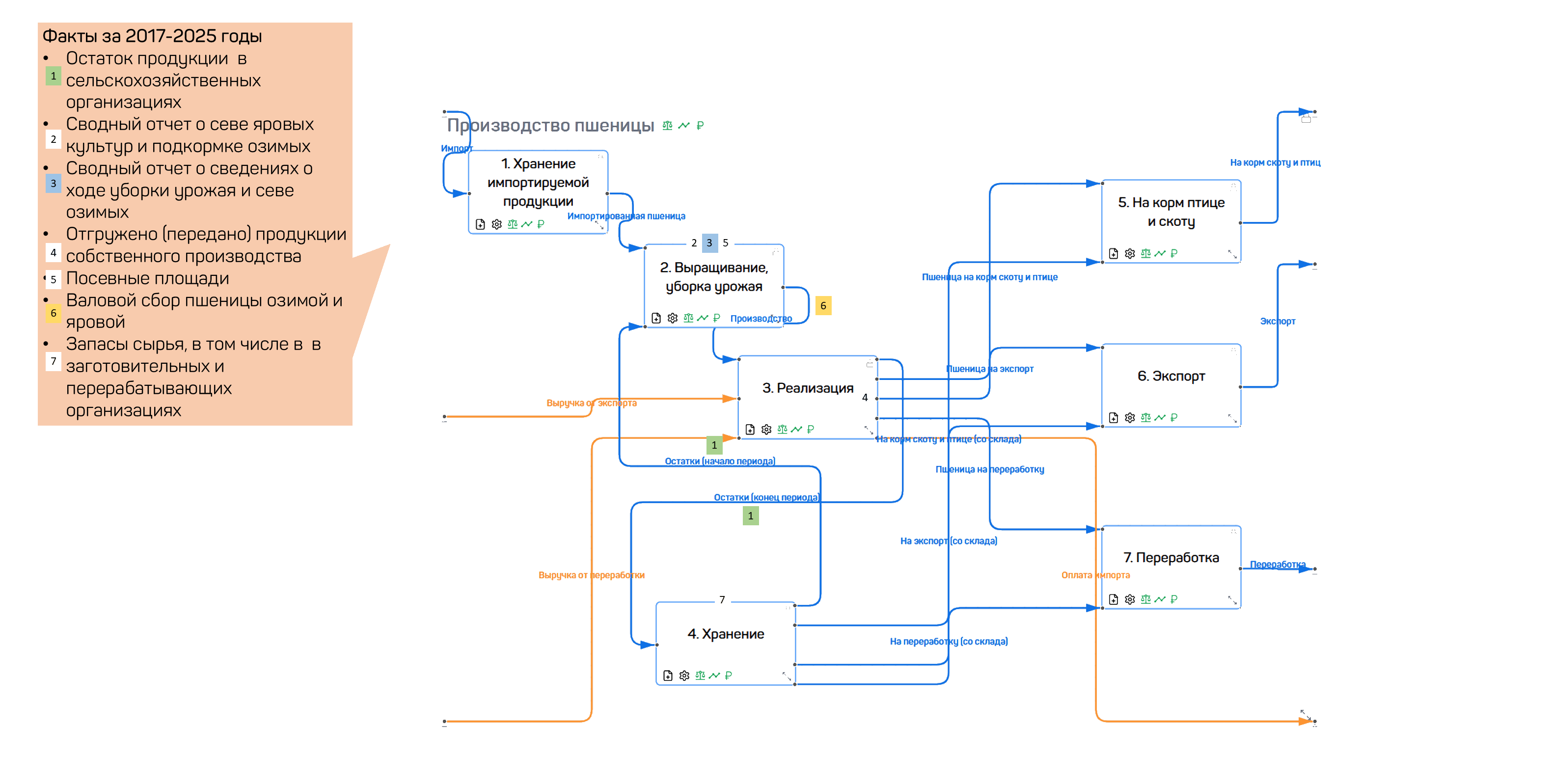
Figure 39 — Technological scheme of wheat production with resource flows
7.4 Data layer
7.4.1 PostgreSQL — relational DBMS
Purpose: Stores transactional data and system metadata.
Stored data:
- Reference books and classifiers
- User data and access rights
- System configuration
- Transactional data
- Model metadata
Characteristics:
- Version: PostgreSQL 14+
- Replication: Master-Slave
- Backup: Daily
- Performance: Up to 10,000 TPS
7.4.2 ClickHouse — analytical DBMS
Purpose: Stores large volumes of analytical data.
Stored data:
- Time series (production, sales, prices)
- Aggregated indicators
- System logs and events
- Calculation results
Characteristics:
- Version: ClickHouse 22+
- Data compression: Up to 10x
- Query speed: Millions of rows/sec
- Partitioning: By time
7.5 Integration layer
7.5.1 ETL module
Purpose: Extracts, transforms, and loads data.
Components:
1. Connectors:
- REST API clients
- ODBC/JDBC drivers
- File parsers (Excel, CSV, XML)
- Web scraping
2. Transformers:
- Data normalization
- Validation and cleaning
- Data enrichment
- Aggregation
3. Loaders:
- Batch loading
- Streaming loading
- Incremental loading
4. Technologies:
- Apache NiFi for visual flow design
- Python for custom transformations
- Apache Kafka for stream processing
7.6 Business logic layer
7.6.1 Analytical module (R/Posit)
Purpose: Statistical analysis and modeling.
Capabilities:
- Descriptive statistics
- Time series (forecast, prophet)
- Correlation analysis
- Regression analysis
- Cluster analysis
Libraries:
tidyverse— data processingforecast— forecastingtargets— computation managementshiny— interactive applicationsggplot2— visualization
Performance:
- Parallel computing
- Result caching
- Incremental calculations
7.6.2 Machine learning and optimization module (Python)
Purpose: Machine learning and optimization.
The platform organizes the use of artificial intelligence technologies in analytical calculations into 5 stages: preprocessing and building a single resource-balance model (NLP/BERT, Anomaly Detection, AutoML), fine-tuning the model (LSTM/GRU, XGBoost/CatBoost, Graph Neural Networks), forecasting (Meta-Learning/Stacking, Bayesian Inference), scenarios and risks (Reinforcement Learning, VAE/GAN, Monte Carlo), and decision optimization (SHAP/LIME, Real-time Monitoring).
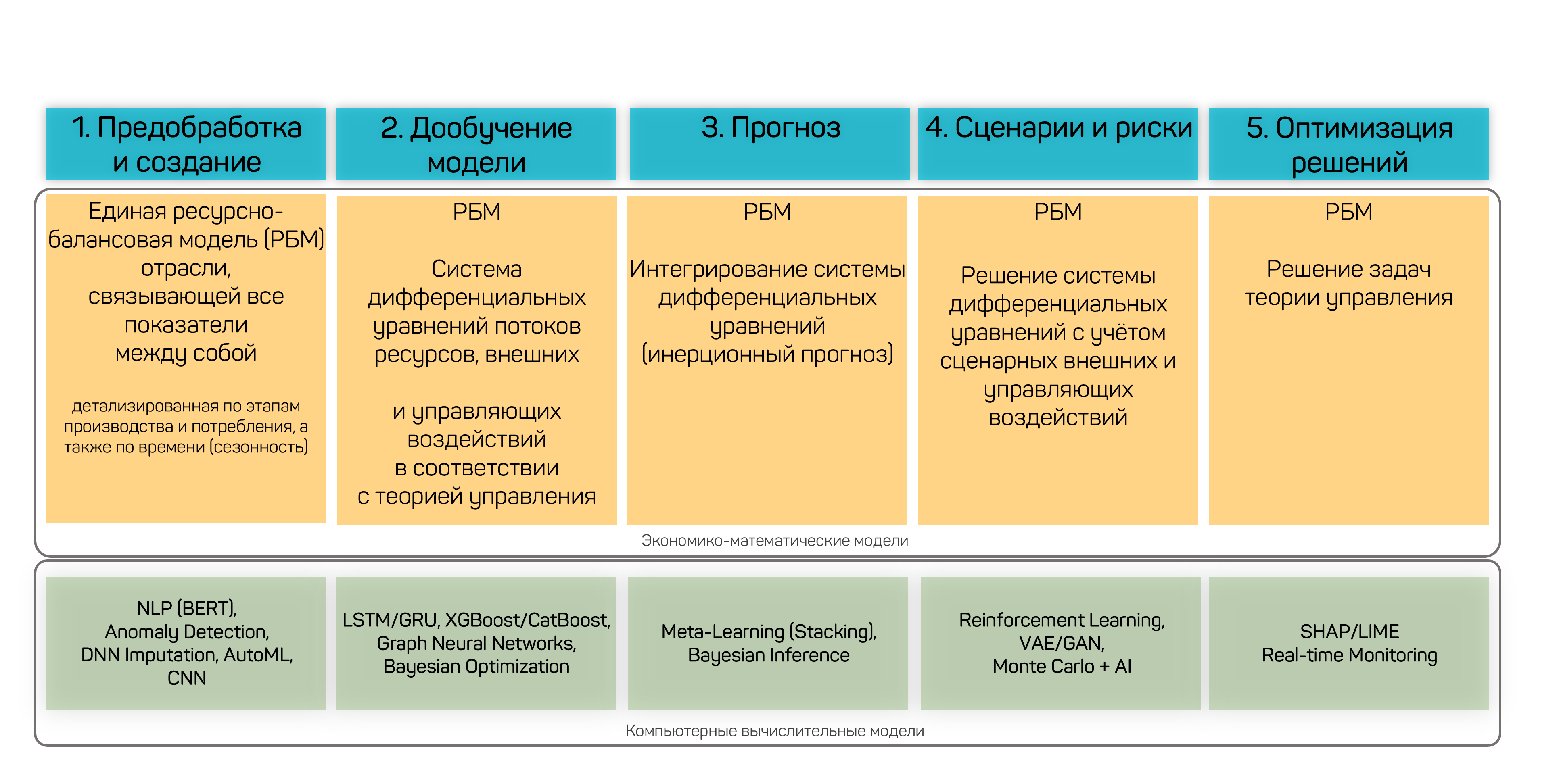
Figure 40 — Use of AI technologies for analytical calculations: 5 stages from preprocessing to optimization
Capabilities:
Machine learning:
- Supervised learning — regression, classification
- Unsupervised learning — clustering
- Time series forecasting
- Deep learning (optional)
Optimization:
- Linear programming
- Integer programming
- Nonlinear optimization
- Genetic algorithms
Libraries:
scikit-learn— ML algorithmsxgboost,lightgbm— gradient boostingscipy.optimize— optimizationpulp,pyomo— mathematical programmingpandas,numpy— data processing
7.6.3 Computing module (Java/C++)
Purpose: High-performance computing.
Use cases:
- Simulations of production processes
- Resource-balance calculations
- Processing large volumes of data
- Time-critical calculations
Technologies:
- Java 17+ for business logic
- C++ for compute-heavy tasks
- Apache Spark for distributed computing
7.7 API layer
7.7.1 REST API services
Purpose: Exposes functionality through an HTTP API.
The EDT platform provides a full-featured REST API for integrating with external systems, automating processes, and accessing data and calculations programmatically. The API follows RESTful architecture principles and supports the standard HTTP methods (GET, POST, PUT, DELETE).
API documentation:
The full interactive API documentation is available at: https://api.dtwin.ru/docs/
The documentation includes:
- A description of every endpoint with sample requests and responses;
- an interactive console for testing the API;
- data schemas and object models;
- error codes and how to handle them;
- integration examples in various programming languages.
Main endpoint groups:
# Data and reference books
GET /api/v1/data/documents # Document list
GET /api/v1/data/kpi # KPI indicators
POST /api/v1/data/import # Data import
GET /api/v1/data/dictionaries # Reference books
# Analytics and calculations
POST /api/v1/analytics/forecast # Forecasting
POST /api/v1/analytics/optimize # Optimization
GET /api/v1/analytics/results # Calculation results
POST /api/v1/analytics/scenarios # Scenario modeling
# External factors
GET /api/v1/factors/list # External factor list
POST /api/v1/factors/update # Factor updates
GET /api/v1/factors/history # Change history
# Monitoring and visualization
GET /api/v1/monitor/dashboard # Dashboard data
GET /api/v1/monitor/alerts # Alerts
GET /api/v1/monitor/sts # STS data
# Administration
GET /api/v1/admin/users # Users
POST /api/v1/admin/config # Configuration
GET /api/v1/admin/logs # System logsSystem of monitored external factors:
The EDT platform includes a subsystem that manages the external factors affecting the enterprise’s production and economic indicators. The system lets you:
- Track changes in macroeconomic indicators (exchange rates, raw material prices, indices);
- automatically update data from external sources through APIs;
- assess how external factors affect the enterprise’s key indicators;
- run scenario analysis when external conditions change;
- generate early warnings about critical changes.
External factors feed into the calculation models and automatically factor into forecasting and optimization.
Technologies and standards:
- Node.js / Express for the API server;
- Swagger/OpenAPI 3.0 for documentation;
- JWT (JSON Web Tokens) for authentication;
- OAuth 2.0 for authorizing external applications;
- Rate limiting to guard against overload;
- CORS for cross-domain requests.
7.8 Presentation layer
7.8.1 Web application
Technologies:
Frontend Framework:
- React 18+ with TypeScript
- Redux for state management
- React Router for navigation
UI Components:
- Material-UI for components
- Styled Components for styles
- Formik for forms
Visualization:
- D3.js for custom charts
- Plotly.js for interactive charts
- Recharts for simple diagrams
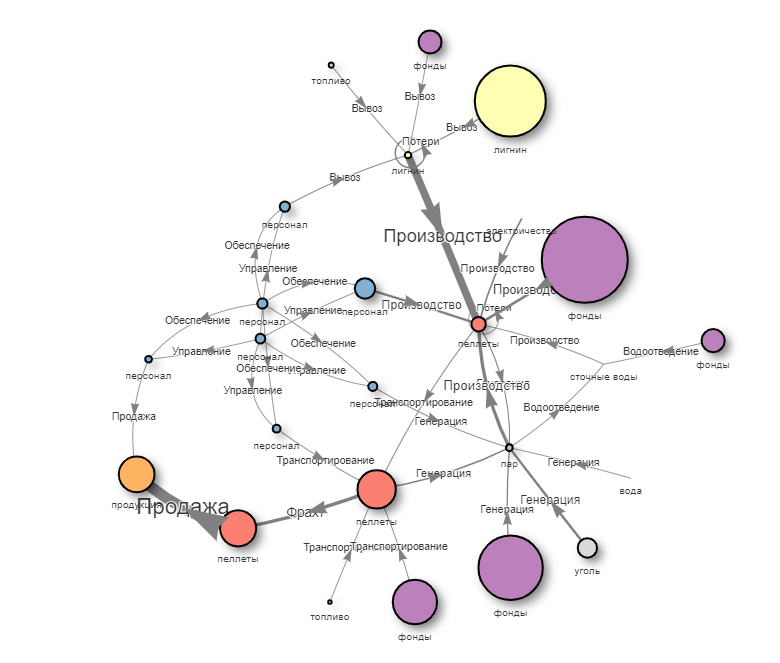
Figure 41 — Dynamic graph of production flows: visualizing the enterprise’s resource connections
Build Tools:
- Vite for fast builds
- ESLint for linting
- Prettier for formatting
7.9 Platform architecture
The platform architecture includes two main contours:
1. City digital twin (external factor analysis, macroeconomic modeling); 2. Enterprise digital twin (production balances, optimization).
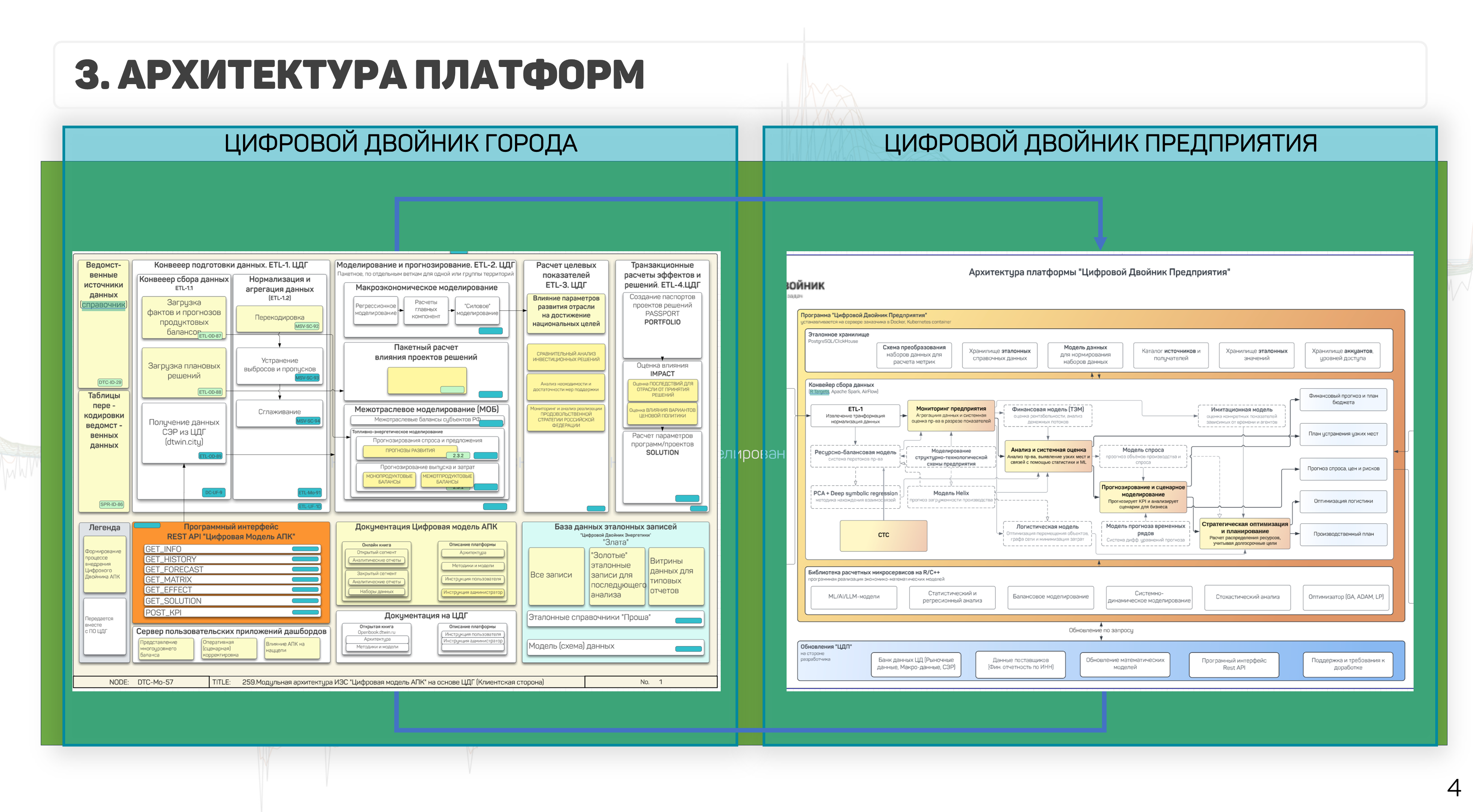
Figure 42 — Platform architecture: City digital twin and Enterprise digital twin
The technology stack of the Unified Digital Platform includes subsystems for authentication (Nginx, Blitz Identity Provider), administration (RabbitMQ, Apache Tomcat, Spring Boot), data collection (Vue.js, PHP, PostgreSQL), analytical calculations (C++, jQuery, a proprietary-format database), integration (GosJava), and storage (Angular, Golang, PostgreSQL, Redis, Nginx).
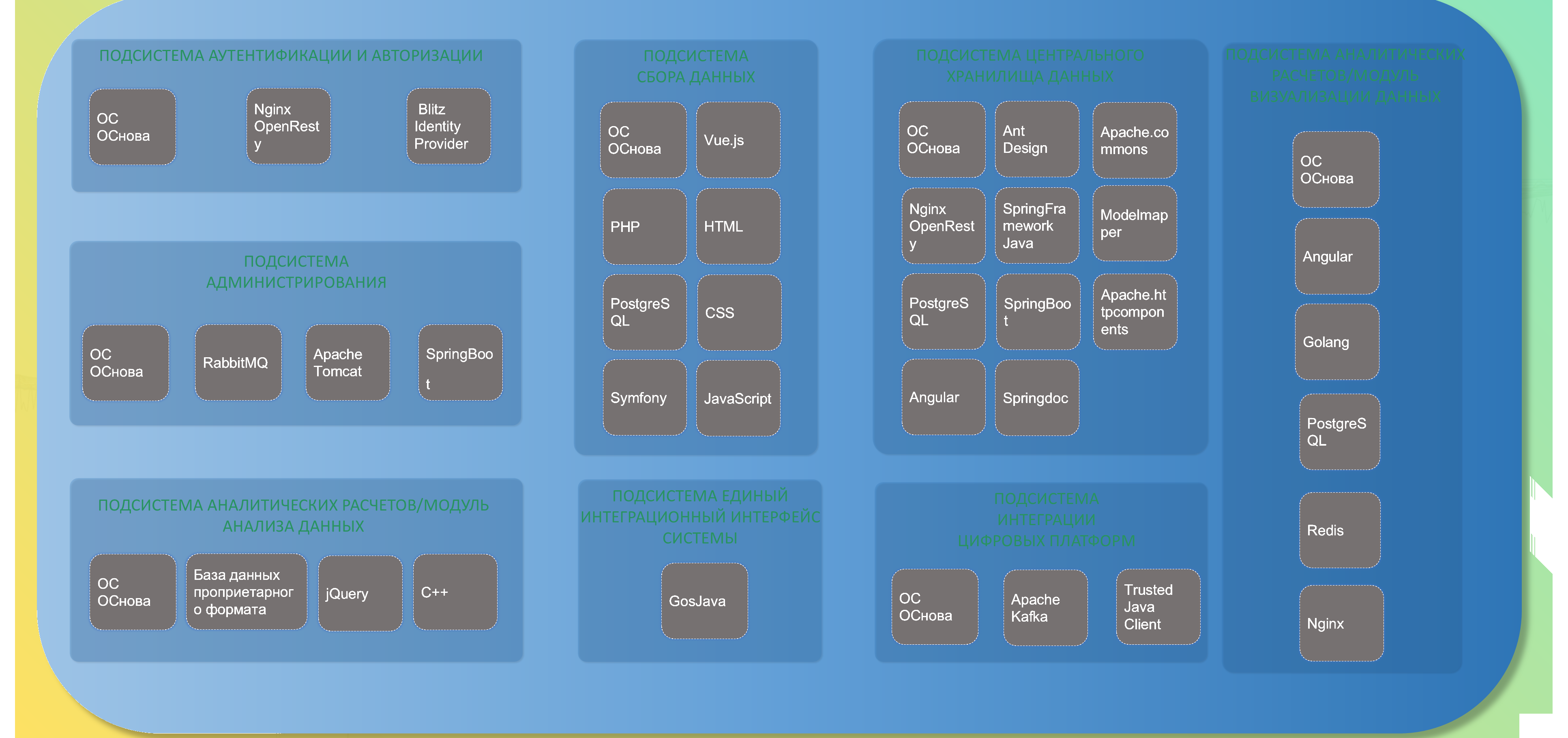
Figure 43 — Technology stack of the Unified Digital Platform
7.10 Infrastructure components
7.10.1 Monitoring and logging
Prometheus + Grafana:
- Performance metrics
- Resource usage
- API response time
- Custom metrics
ELK Stack (Elasticsearch, Logstash, Kibana):
- Centralized logging
- Log search
- Event visualization
- Error analysis
7.10.2 Caching
Redis:
- API response cache
- User sessions
- Temporary data
- Task queues
Memcached:
- Calculation result cache
- Database query cache